Three model variants.
Nine ablations across 3 architectures and 3 input modalities. CVAE and Transformer share a ResNet18 visual encoder; CNN-BC uses ResNet34.
CVAE / ACT
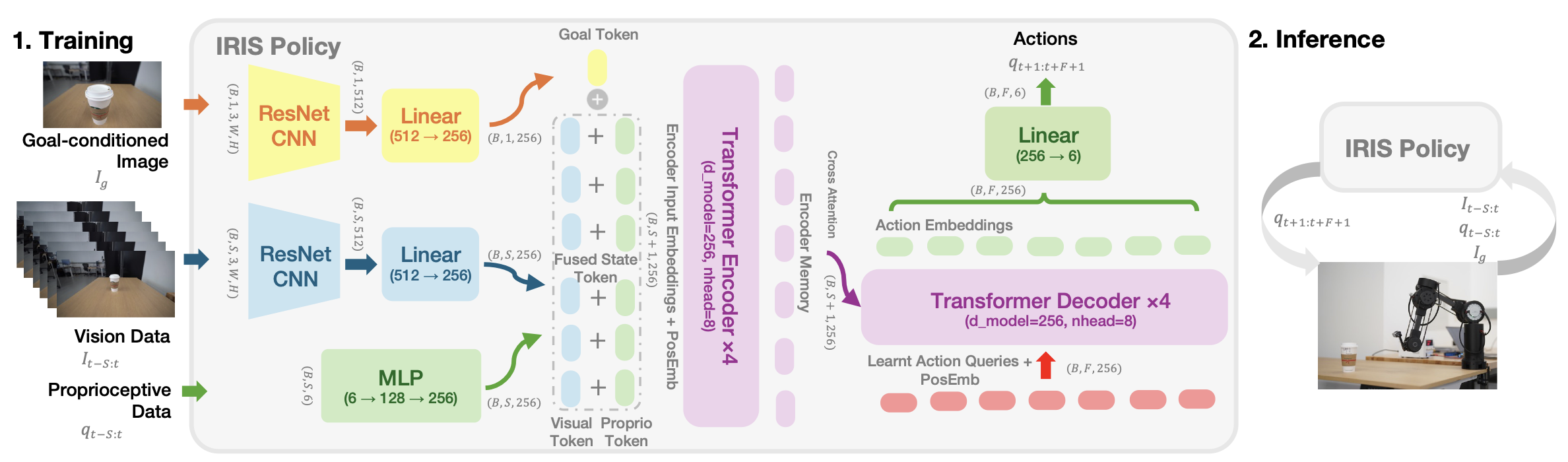
Conditional Variational Autoencoder with a Transformer decoder that predicts a chunk of F=15 future actions. Latent variable z encodes multi-modal action distribution. Inspired by ACT.
- ResNet18 + Spatial Softmax visual encoder
- d_model=256 · 4 enc + 4 dec layers · 8 heads
- Input: S=8 frame window + joint history + goal image
- Output: F=15 joint angle targets
- Loss: MSE + β·KL + λ·Smoothness
- latent_dim=32, β=0.01
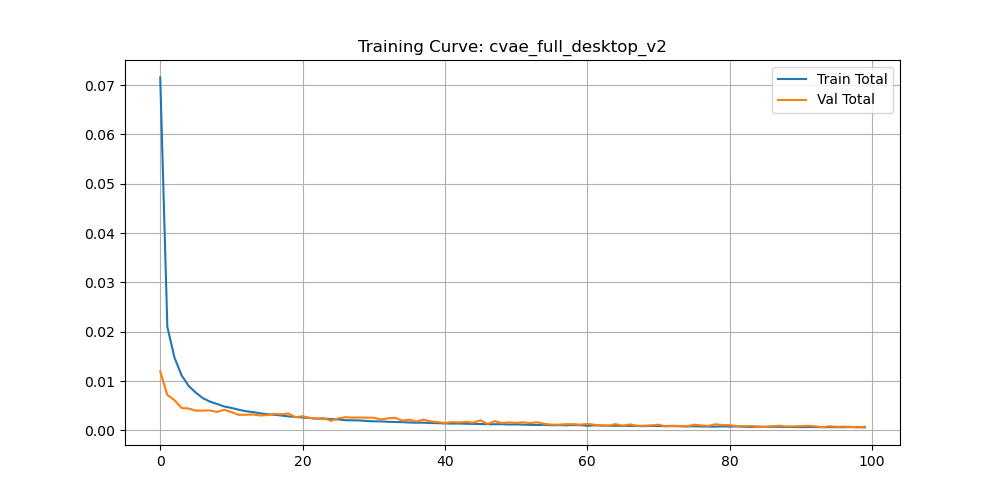
python train_cvae.py \ --name MY_RUN \ --model cvae_full \ --loss loss_kl \ --data_roots ~/Desktop/final_RGB_joint_goal \ --checkpoint_dir ~/Desktop/checkpoints \ --batch_size 64 \ --epochs 100 \ --latent_dim 32 \ --beta 0.01
Auto-resumes from last checkpoint if interrupted. ~8 h on RTX 4090 for 100 epochs.
Deterministic Transformer
Sequence-to-sequence Transformer without a latent variable. Ablates the stochastic component to measure the contribution of z in the CVAE.
- Same ResNet18 encoder as CVAE
- Input: S=8 frame window + joint state + goal image
- Output: F=15 joint angle targets
- Loss: MSE + smoothness
- No latent variable (z removed)
python train_determinstic.py \ --name MY_RUN \ --model det_rgb \ --loss mse_smooth \ --data_roots ~/Desktop/final_RGB_only \ --checkpoint_dir ~/Desktop/checkpoints
Also supports det_visual and det_full input modalities.
CNN-BC
ResNet34 + MLP behavior cloning baseline. Single-step prediction without action chunking or temporal modeling. Lower bound on sequence modeling capability.
- Backbone: ResNet34 (larger than primary models)
- Input: single RGB frame + current joint state
- Output: next-step joint angle targets
- Loss: MSE only
- No temporal modeling or latent variable
python train_cnn_bc.py \ --name MY_RUN \ --data_roots ~/Desktop/final_RGB_joint_goal \ --checkpoint_dir ~/Desktop/checkpoints
Fastest to train. Use as a sanity-check lower bound before running the full CVAE pipeline.
Full system — ResNet18 → Spatial Softmax → CVAE Transformer
Model variants: {arch}_{obs} where arch ∈ {cvae, det, vanilla_bc}
and obs ∈ {rgb, visual, full}. Primary model: cvae_full.