
CRV 2026
IRIS
Learning-Driven Cinema Robot Arm
for Visuomotor Motion Control
Learning-Driven Cinema Robot Arm
for Visuomotor Motion Control
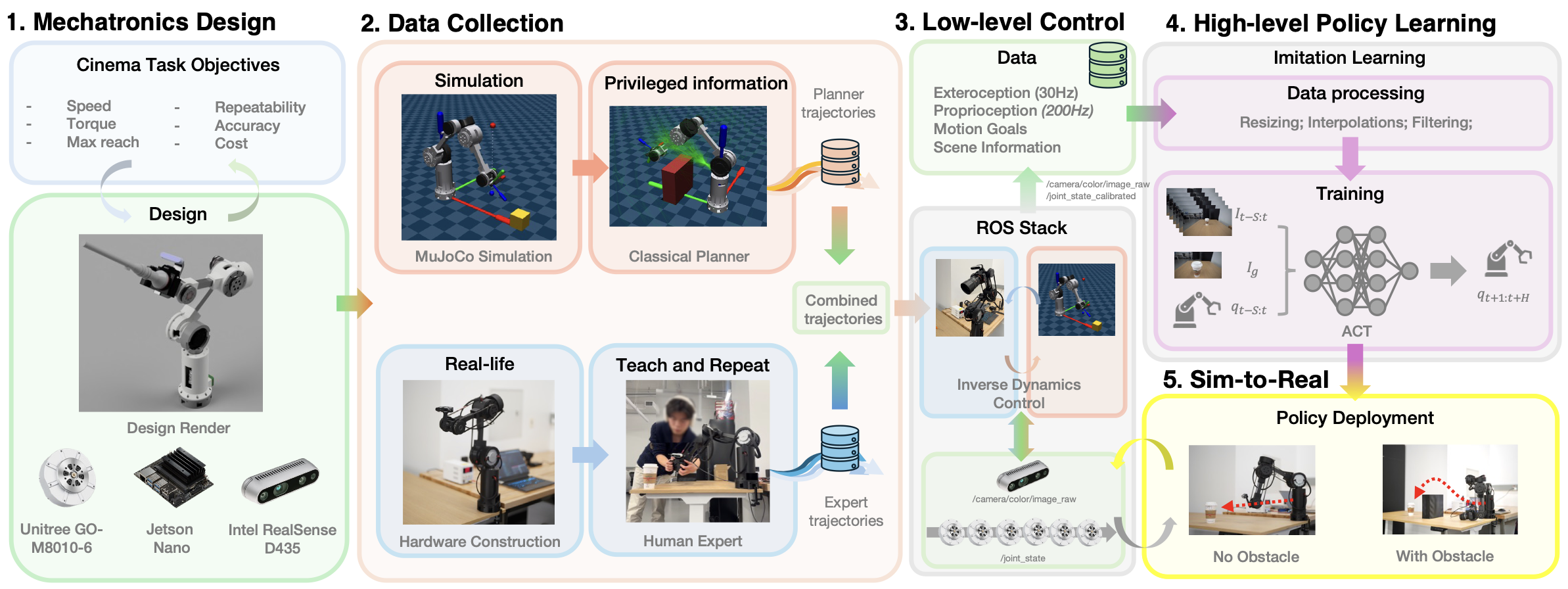
IRIS is a low-cost, 3D-printed 6-DOF cinema robot arm that learns cinematic camera motions from human demonstrations via goal-conditioned visuomotor imitation learning. At ~$992 in materials, it achieves 97% of expert visual alignment and 6× smoother motion than its human teachers. All hardware designs, simulation, and training code are fully open-sourced.
Sub-$1K 6-DOF arm with quasi-direct-drive actuators. STEP files, BOM, and wiring docs released.
MuJoCo physics twin with analytical FK/IK, RRT* and potential-field planners, and cinema shot modes.
Goal-conditioned CVAE transformer trained from kinesthetic demonstrations. 9 ablation variants evaluated.
200 Hz RS-485 driver, joint calibration, sim-to-real live mirroring, teach-and-repeat workflow.
STEP files, bill of materials, actuator specs, and wiring documentation.
200 Hz RS-485 driver, calibration pipeline, teleoperation, and data recording.
Physics twin with FK/IK, RRT* planning, and cinema motion modes.
CVAE transformer, deterministic baseline, CNN-BC — training and deployment.
IRIS — Cinema Shot Execution

Crane — Vertical rise while tracking a fixed subject

Dolly — Linear push-in / pull-out

Pan — Lateral arc sweep

Kinesthetic teaching — operator physically guides the arm

CVAE Full policy deployed on real hardware — 46.2% task success

| Method | Success | Vis. Align. | Jerk |
|---|---|---|---|
| Expert | 90.0% | 0.874 | 3.64 |
| CVAE Full | 90.0% | 0.847 | 0.61 |
| Incremental | 0.0% | 0.636 | 0.83 |
| RGB Only | 0.0% | 0.584 | 1.65 |
| Visual | 0.0% | 0.536 | 1.59 |
| RRT* | 10.0% | 0.636 | 0.22 |
Visual Alignment = ResNet18 cosine similarity to goal image. Jerk in m/s³.
@inproceedings{cheng2026iris,
title = {{IRIS}: Learning-Driven Task-Specific Cinema Robot Arm
for Visuomotor Motion Control},
author = {Qilong Cheng and Matthew Mackay and Ali Bereyhi},
booktitle = {23rd Conference on Robots and Vision},
year = {2026},
url = {https://arxiv.org/abs/2602.17537}
}