
TINTIN
Thrust-Integrated Neural Touchdown with Reinforcement Learning and INertial Navigation
Thrust-Integrated Neural Touchdown with Reinforcement Learning and INertial Navigation
We present a Deep Reinforcement Learning (DRL) approach for Integrated Guidance and Control (IGC) of a variable-mass 6-DoF lunar lander. The method replaces traditional trajectory-planning and control loops.
A high-fidelity 6-DoF MuJoCo environment modeling variable-mass rigid-body dynamics and thrust-attitude coupling.
A policy trained with curriculum learning and domain randomization for robustness across a deployment ellipse.
Achieves high Monte Carlo success rates and quasi-fuel-optimal performance.
The lunar rocket-landing pipeline comprises three main phases: Entry, Flip and Altitude Capture, and Terminal Landing Burn
The problem is modeled as a continuous-control Markov Decision Process (MDP) with a control objective of minimum-fuel landing while stabilizing position, attitude, and vertical descent toward the designated target.
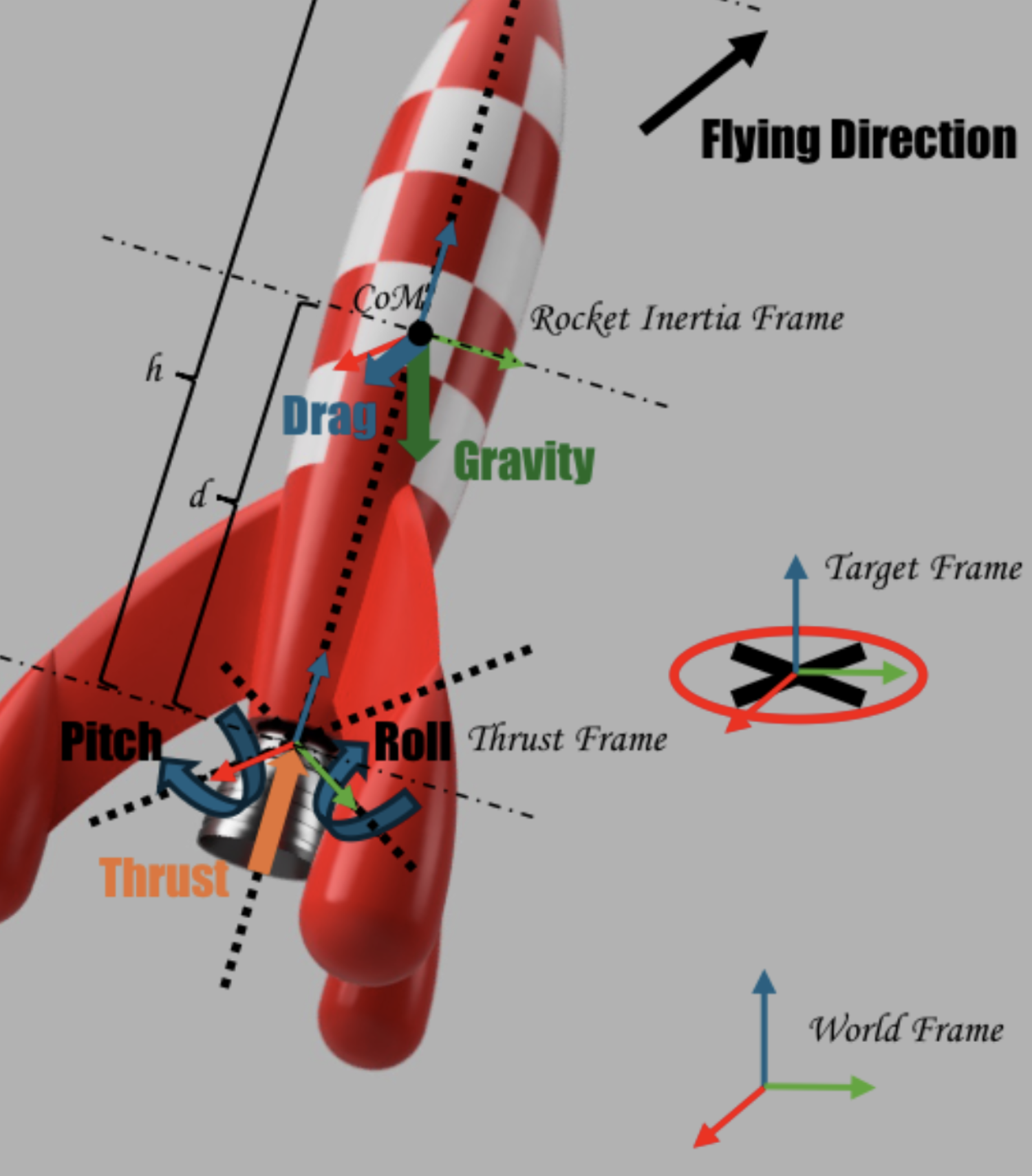
The Deep Reinforcement Learning algorithm used is Soft Actor-Critic (SAC). The raw observation includes the full translational and rotational state $o_{t}=[p,v,q,\omega,m]\in\mathbb{R}^{14}$. The action vector is the commanded thrust and gimbal angles: $a_{t}=[T,\theta_{p},\theta_{y}]$.
Reward shaping balances dense and sparse rewards to optimize training speed. Shaping terms encourage minimizing attitude tilt ($15 \cos(\theta)$), reducing vertical descent, decreasing lateral distance, and shortening flight duration. Successful soft landings receive a terminal bonus of $1000+5(\frac{m_{fuel}}{m_{0}})$.
Curriculum learning progressively tightens success criteria once the policy achieves an 80% success rate at each level. Domain randomization improves robustness by varying initial conditions like pose, velocity, and mass.




We compared SAC against DQN and PPO to identify the best algorithm for the complex 6-DoF lander dynamics. SAC demonstrated the fastest convergence and most consistent results.

SAC achieved the highest success rate and converged fastest to the optimal solution. Episode Reward and Fuel Remaining stabilized quickly.

PPO converged to stable behavior after over 10 million total timesteps but resulted in suboptimal thrusting.

DQN failed to produce a reliable 6-DoF controller, likely due to coarse action discretization (27 discrete actions).
The resulting SAC policy achieved robust soft landings across wide variations in initial pose, velocity, and mass. The Monte Carlo failure analysis identified the primary sources of failure.
* 43% of episodes terminate due to excessive tilt. * 27% terminate due to lateral drift. * 19% terminate due to high terminal velocity.

The SAC policy reliably handles the global descent and flip maneuvers. However, failures are dominated by limited terminal stability, suggesting difficulties with late-phase attitude stabilization.
Success is defined as touchdown within 80 m of target, tilt $\le 15^{\circ}$, and vertical speed between 0 and 20 m/s.

TINTIN presents a deep reinforcement learning approach for Integrated Guidance and Control (IGC) of a variable-mass 6-DoF lunar lander. The system is trained on a high-fidelity MuJoCo simulator modeling mass depletion and thrust-attitude coupling.
The rocket is modeled as a 100 m vehicle with a dry mass of $5.00\times10^{5}$ kg, and the engine offset is 30 m below the CoM.

We demonstrated a DRL-based Integrated Guidance and Control (IGC) system for 6-DoF planetary powered descent, validating the concept for aerospace guidance and control. The SAC policy successfully learned to regulate the coupled translational and rotational dynamics of the single-gimbaled lander.
Despite strong global guidance behavior, the dominant failures arise in the terminal phase. Future work will focus on integrating physics-model priors and residual RL to improve terminal stability, training robustness, and increase touchdown reliability.